|
Google Ngram viewer是一个有趣和有用的工具,它使用谷歌从书本中扫描来的海量的数据宝藏,绘制出单词使用量随时间的变化。举个例子,单词Python(区分大小写):
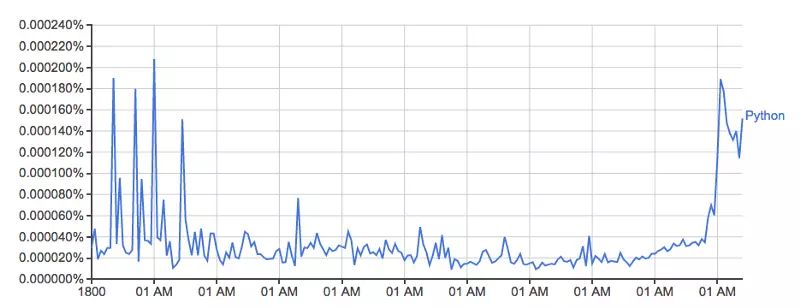
这幅图来自:books.google.com/ngrams/grap…,描绘了单词 'Python' 的使用量随时间的变化。
它是由谷歌的n-gram数据集驱动的,根据书本印刷的每一个年份,记录了一个特定单词或词组在谷歌图书的使用量。然而这并不完整(它并没有包含每一本已经发布的书!),数据集中有成千上百万的书,时间上涵盖了从 16 世纪到 2008 年。数据集可以免费从这里下载。
我决定使用 Python 和我新的数据加载库PyTubes来看看重新生成上面的图有多容易。
挑战
1-gram 的数据集在硬盘上可以展开成为 27 Gb 的数据,这在读入 python 时是一个很大的数据量级。Python可以轻易地一次性地处理千兆的数据,但是当数据是损坏的和已加工的,速度就会变慢而且内存效率也会变低。
总的来说,这 14 亿条数据(1,430,727,243)分散在 38 个源文件中,一共有 2 千 4 百万个(24,359,460)单词(和词性标注,见下方),计算自 1505 年至 2008 年。
当处理 10 亿行数据时,速度会很快变慢。并且原生 Python 并没有处理这方面数据的优化。幸运的是,numpy真的很擅长处理大体量数据。 使用一些简单的技巧,我们可以使用 numpy 让这个分析变得可行。
在 python/numpy 中处理字符串很复杂。字符串在 python 中的内存开销是很显著的,并且 numpy 只能够处理长度已知而且固定的字符串。基于这种情况,大多数的单词有不同的长度,因此这并不理想。
Loading the data
下面所有的代码/例子都是运行在8 GB 内存的 2016 年的 Macbook Pro。 如果硬件或云实例有更好的 ram 配置,表现会更好。
1-gram 的数据是以 tab 键分割的形式储存在文件中,看起来如下:
Python158742
Python162111
Python165122
Python165911
每一条数据包含下面几个字段:
1.Word
2.Year of Publication
3.Total number of times the word was seen
4.Total number of books containing the word
为了按照要求生成图表,我们只需要知道这些信息,也就是:
1. 这个单词是我们感兴趣的?
2. 发布的年份
3. 单词使用的总次数
通过提取这些信息,处理不同长度的字符串数据的额外消耗被忽略掉了,但是我们仍然需要对比不同字符串的数值来区分哪些行数据是有我们感兴趣的字段的。这就是 pytubes 可以做的工作:
import tubes
FILES = glob.glob(path.expanduser("~/src/data/ngrams/1gram/googlebooks*"))
WORD = "Python"
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.multi(lambda row: (
row.get(0).equals(WORD.encode('utf-8')),
row.get(1).to(int),
row.get(2).to(int)
))
)
差不多 170 秒(3 分钟)之后,onegrams_ 是一个 numpy 数组,里面包含差不多 14 亿行数据,看起来像这样(添加表头部为了说明):
╒═══════════╤════════╤═════════╕
│ Is_Word │ Year │ Count │
╞═══════════╪════════╪═════════╡
│ 0 │ 1799 │ 2 │
├───────────┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1805 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1811 │ 1 │
├───────────┼────────┼─────────┤
│ 0 │ 1820 │ ... │
╘═══════════╧════════╧═════════╛
从这开始,就只是一个用 numpy 方法来计算一些东西的问题了:
每一年的单词总使用量
谷歌展示了每一个单词出现的百分比(某个单词在这一年出现的次数/所有单词在这一年出现的总数),这比仅仅计算原单词更有用。为了计算这个百分比,我们需要知道单词总量的数目是多少。
幸运的是,numpy让这个变得十分简单:
last_year = 2008
YEAR_COL = '1'
COUNT_COL = '2'
year_totals, bins = np.histogram(
one_grams[YEAR_COL],
density=False,
range=(0, last_year+1),
bins=last_year + 1,
weights=one_grams[COUNT_COL]
)
绘制出这个图来展示谷歌每年收集了多少单词:
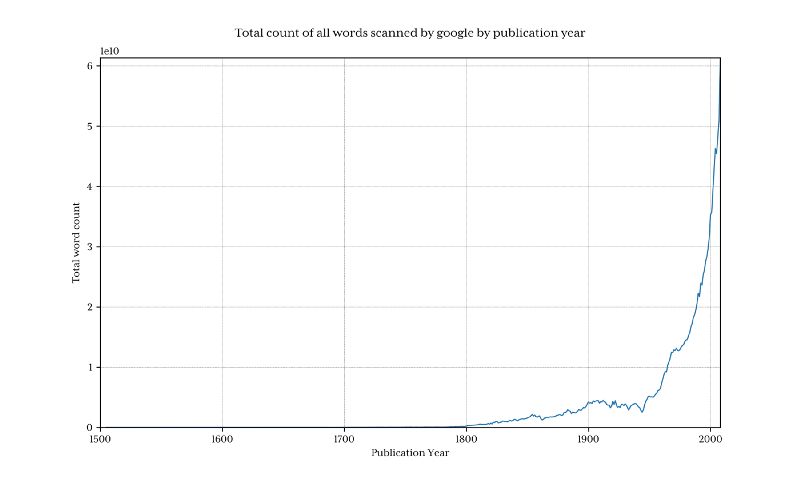
很清楚的是在 1800 年之前,数据总量下降很迅速,因此这回曲解最终结果,并且会隐藏掉我们感兴趣的模式。为了避免这个问题,我们只导入 1800 年以后的数据:
one_grams_tube = (tubes.Each(FILES)
.read_files()
.split()
.tsv(headers=False)
.skip_unless(lambda row: row.get(1).to(int).gt(1799))
.multi(lambda row: (
row.get(0).equals(word.encode('utf-8')),
row.get(1).to(int),
row.get(2).to(int)
))
)
这返回了 13 亿行数据(1800 年以前只有 3.7% 的的占比)
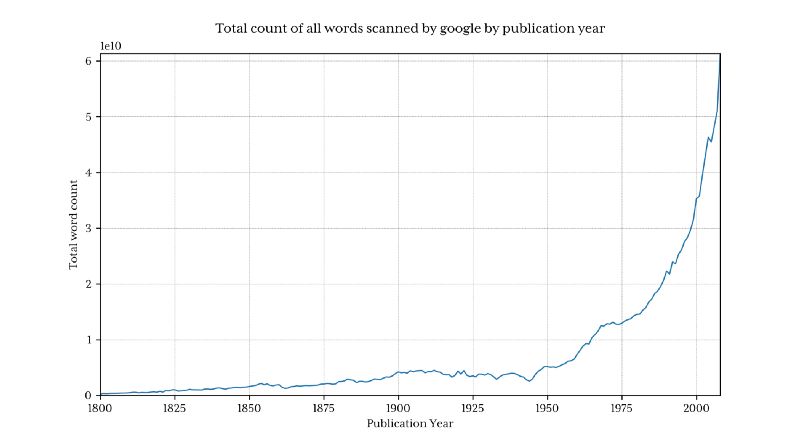
Python 在每年的占比百分数
获得 python 在每年的占比百分数现在就特别的简单了。
使用一个简单的技巧,创建基于年份的数组,2008 个元素长度意味着每一年的索引等于年份的数字,因此,举个例子,1995 就只是获取 1995 年的元素的问题了。
这都不值得使用 numpy 来操作:
word_rows = one_grams[IS_WORD_COL]
word_counts = np.zeros(last_year+1)
for _, year, count in one_grams[word_rows]:
word_counts[year] += (100*count) / year_totals[year]
绘制出 word_counts 的结果:
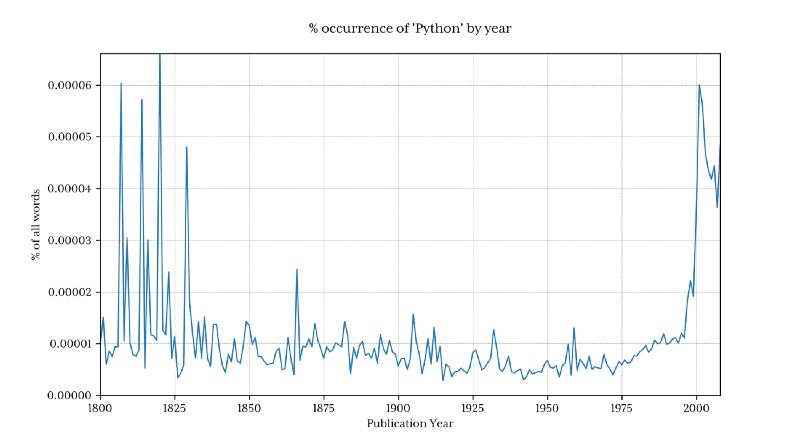
形状看起来和谷歌的版本差不多
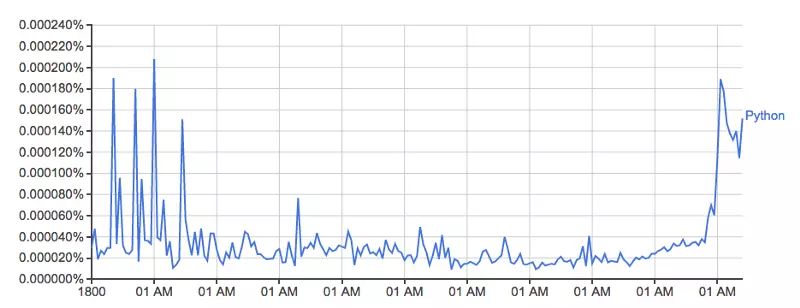
实际的占比百分数并不匹配,我认为是因为下载的数据集,它包含的用词方式不一样(比如:Python_VERB)。这个数据集在 google page 中解释的并不是很好,并且引起了几个问题:
人们是如何将 Python 当做动词使用的?
'Python' 的计算总量是否包含 'Python_VERB'?等
幸运的是,我们都清楚我使用的方法生成了一个与谷歌很像的图标,相关的趋势都没有被影响,因此对于这个探索,我并不打算尝试去修复。
性能
谷歌生成图片在 1 秒钟左右,相较于这个脚本的 8 分钟,这也是合理的。谷歌的单词计算的后台会从明显的准备好的数据集视图中产生作用。
举个例子,提前计算好前一年的单词使用总量并且把它存在一个单独的查找表会显著的节省时间。同样的,将单词使用量保存在单独的数据库/文件中,然后建立第一列的索引,会消减掉几乎所有的处理时间。
这次探索确实展示了,使用 numpy 和 初出茅庐的 pytubes 以及标准的商用硬件和 Python,在合理的时间内从十亿行数据的数据集中加载,处理和提取任意的统计信息是可行的,
语言战争
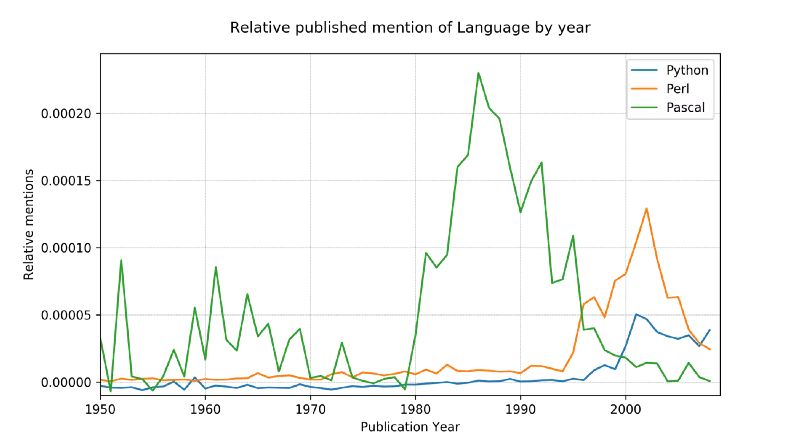
为了用一个稍微更复杂的例子来证明这个概念,我决定比较一下三个相关提及的编程语言:Python,Pascal,和Perl.
源数据比较嘈杂(它包含了所有使用过的英文单词,不仅仅是编程语言的提及,并且,比如,python 也有非技术方面的含义!),为了这方面的调整, 我们做了两个事情:
只有首字母大写的名字形式能被匹配(Python,不是 python)
每一个语言的提及总数已经被转换到了从 1800 年到 1960 年的百分比平均数,考虑到 Pascal 在 1970 年第一次被提及,这应该有一个合理的基准线。
结果:
对比谷歌 (没有任何的基准线调整):
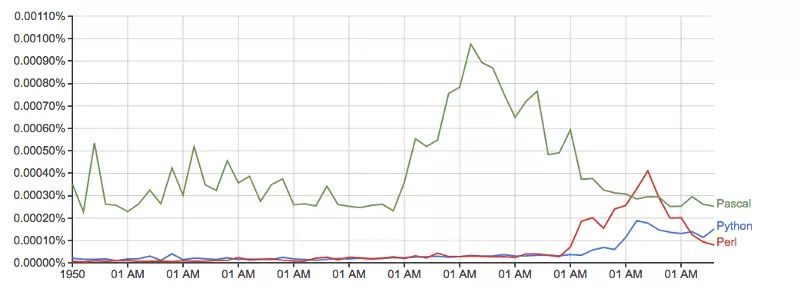
运行时间: 只有 10 分钟多一点
代码:gist.github.com/stestagg/91…
以后的 PyTubes 提升
在这个阶段,pytubes 只有单独一个整数的概念,它是 64 比特的。这意味着 pytubes 生成的 numpy 数组对所有整数都使用 i8 dtypes。在某些地方(像 ngrams 数据),8 比特的整型就有点过度,并且浪费内存(总的 ndarray 有 38Gb,dtypes 可以轻易的减少其 60%)。 我计划增加一些等级 1,2 和 4 比特的整型支持(github.com/stestagg/py…)
更多的过滤逻辑 - Tube.skip_unless() 是一个比较简单的过滤行的方法,但是缺少组合条件(AND/OR/NOT)的能力。这可以在一些用例下更快地减少加载数据的体积。
更好的字符串匹配 —— 简单的测试如下:startswith, endswith, contains, 和 isoneof 可以轻易的添加,来明显地提升加载字符串数据是的有效性。
一如既往,非常欢迎大家patches!

原文标题:使用 Python 分析 14 亿条数据
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
收藏
人收藏
扫一扫,分享给好友
复制链接分享
评论
发布评论请先 登录
相关推荐
python网络爬虫概述
网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
网络爬虫按照...
发表于 03-21 16:51 •
353次
阅读
python网络爬虫概述
网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息....
![的头像]() python爬虫知识分享 发表于 03-21 16:50 •
33次
阅读
python中urllib3和requests的使用
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验证和Cookies,以及Hander头信息处...
发表于 03-21 16:08 •
275次
阅读
python中urllib3库和requests库的使用
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验....
python爬虫知识分享 发表于 03-21 16:50 •
33次
阅读
python中urllib3和requests的使用
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验证和Cookies,以及Hander头信息处...
发表于 03-21 16:08 •
275次
阅读
python中urllib3库和requests库的使用
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验....
![的头像]() python爬虫知识分享 发表于 03-21 16:08 •
75次
阅读
工业物联网风口:武汉裕诚科汇紧抓发展机遇
武汉裕诚科汇紧抓产业发展机遇,与原厂和代理商合作,引入CYPRESS(赛普拉斯)工业级系列芯片(FM....
发表于 03-21 15:46 •
107次
阅读
python正则表达式中的常用函数
编译正则表达式模式,返回一个正则对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可....
python爬虫知识分享 发表于 03-21 16:08 •
75次
阅读
工业物联网风口:武汉裕诚科汇紧抓发展机遇
武汉裕诚科汇紧抓产业发展机遇,与原厂和代理商合作,引入CYPRESS(赛普拉斯)工业级系列芯片(FM....
发表于 03-21 15:46 •
107次
阅读
python正则表达式中的常用函数
编译正则表达式模式,返回一个正则对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可....
![的头像]() python爬虫知识分享 发表于 03-18 16:12 •
299次
阅读
python正则表达式中的常用函数
1、compile():编译正则表达式模式,返回一个正则对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高...
发表于 03-18 16:12 •
2762次
阅读
python正则表达式数量词
这部分理解一下数量词,为什么要用数量词,想想都知道,如果你要匹配几十上百的字符时,难道你要一个一个的写,所以就出现了数量...
发表于 03-18 16:05 •
2810次
阅读
详解python正则表达式数量词
这部分理解一下数量词,为什么要用数量词,想想都知道,如果你要匹配几十上百的字符时,难道你要一个一个的....
python爬虫知识分享 发表于 03-18 16:12 •
299次
阅读
python正则表达式中的常用函数
1、compile():编译正则表达式模式,返回一个正则对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高...
发表于 03-18 16:12 •
2762次
阅读
python正则表达式数量词
这部分理解一下数量词,为什么要用数量词,想想都知道,如果你要匹配几十上百的字符时,难道你要一个一个的写,所以就出现了数量...
发表于 03-18 16:05 •
2810次
阅读
详解python正则表达式数量词
这部分理解一下数量词,为什么要用数量词,想想都知道,如果你要匹配几十上百的字符时,难道你要一个一个的....
![的头像]() python爬虫知识分享 发表于 03-18 16:05 •
295次
阅读
化工厂定位人员系统在智能二道门的应用
化工安全管理制约着行业的发展,国家应急部办公厅关于印发《“工业互联网+危化安全生产”试点建设方案》的....
发表于 03-18 11:33 •
8次
阅读
大数据的四大特征
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能....
python爬虫知识分享 发表于 03-18 16:05 •
295次
阅读
化工厂定位人员系统在智能二道门的应用
化工安全管理制约着行业的发展,国家应急部办公厅关于印发《“工业互联网+危化安全生产”试点建设方案》的....
发表于 03-18 11:33 •
8次
阅读
大数据的四大特征
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能....
![的头像]() 传感器技术 发表于 03-18 10:53 •
358次
阅读
python正则表达式字符集
字符集是由一对方括号 “[]” 括起来的字符集合。使用字符集,可以匹配多个字符中的一个。
举个例子,比如你使用 C[ET]O 匹...
发表于 03-17 16:48 •
2893次
阅读
python正则表达式字符集
字符集是由一对方括号 “[]” 括起来的字符集合。使用字符集,可以匹配多个字符中的一个。 举个例子,....
传感器技术 发表于 03-18 10:53 •
358次
阅读
python正则表达式字符集
字符集是由一对方括号 “[]” 括起来的字符集合。使用字符集,可以匹配多个字符中的一个。
举个例子,比如你使用 C[ET]O 匹...
发表于 03-17 16:48 •
2893次
阅读
python正则表达式字符集
字符集是由一对方括号 “[]” 括起来的字符集合。使用字符集,可以匹配多个字符中的一个。 举个例子,....
![的头像]() python爬虫知识分享 发表于 03-17 16:48 •
320次
阅读
初识 Python 正则表达式
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模...
发表于 03-17 16:44 •
2342次
阅读
初识 Python 正则表达式
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一....
python爬虫知识分享 发表于 03-17 16:48 •
320次
阅读
初识 Python 正则表达式
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模...
发表于 03-17 16:44 •
2342次
阅读
初识 Python 正则表达式
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一....
![的头像]() python爬虫知识分享 发表于 03-17 16:44 •
309次
阅读
千方科技筑牢智慧交通四全底座 金溢科技助力全国首个无杆ETC站落地
在第十六届ITS中国智能交通年会上,千方科技总裁潘璠对“千方科技Omni-T全域交通解决方案”进....
python爬虫知识分享 发表于 03-17 16:44 •
309次
阅读
千方科技筑牢智慧交通四全底座 金溢科技助力全国首个无杆ETC站落地
在第十六届ITS中国智能交通年会上,千方科技总裁潘璠对“千方科技Omni-T全域交通解决方案”进....
![的头像]() 牵手一起梦 发表于 03-17 15:46 •
465次
阅读
中兴通讯发布新数字化运营平台VMAX Apple发布全新电脑和显示产品
VMAX支持跨域端到端的业务感知自愈,采用AI自学习方式,通过跨域数据关联及深度分析,可实现业务....
牵手一起梦 发表于 03-17 15:46 •
465次
阅读
中兴通讯发布新数字化运营平台VMAX Apple发布全新电脑和显示产品
VMAX支持跨域端到端的业务感知自愈,采用AI自学习方式,通过跨域数据关联及深度分析,可实现业务....
![的头像]() 牵手一起梦 发表于 03-17 09:18 •
280次
阅读
从 yield 开始入门python协程
简单介绍 yield本篇文章会先向你介绍一个陌生的 Python 关键词,他和 return 就像一对新兄弟,有相似之处,又各有不同。
相似的...
发表于 03-16 16:21 •
153次
阅读
从yield开始入门python协程
本篇文章会先向你介绍一个陌生的 Python 关键词,他和 return 就像一对新兄弟,有相似之处....
牵手一起梦 发表于 03-17 09:18 •
280次
阅读
从 yield 开始入门python协程
简单介绍 yield本篇文章会先向你介绍一个陌生的 Python 关键词,他和 return 就像一对新兄弟,有相似之处,又各有不同。
相似的...
发表于 03-16 16:21 •
153次
阅读
从yield开始入门python协程
本篇文章会先向你介绍一个陌生的 Python 关键词,他和 return 就像一对新兄弟,有相似之处....
![的头像]() python爬虫知识分享 发表于 03-16 16:20 •
224次
阅读
线程池创建的两种方法
1. 使用内置模块在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu的大量开...
发表于 03-16 16:15 •
139次
阅读
python创建线程池的两种方法
在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu....
python爬虫知识分享 发表于 03-16 16:20 •
224次
阅读
线程池创建的两种方法
1. 使用内置模块在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu的大量开...
发表于 03-16 16:15 •
139次
阅读
python创建线程池的两种方法
在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu....
![的头像]() python爬虫知识分享 发表于 03-16 16:15 •
216次
阅读
易华录与京东科技达成战略合作 中兴通讯2021年双创历史新高
易华录与京东科技集团在北京签署战略合作协议,共同推进在智能城市、数字经济、企业数字化等领域的深入....
python爬虫知识分享 发表于 03-16 16:15 •
216次
阅读
易华录与京东科技达成战略合作 中兴通讯2021年双创历史新高
易华录与京东科技集团在北京签署战略合作协议,共同推进在智能城市、数字经济、企业数字化等领域的深入....
![的头像]() 牵手一起梦 发表于 03-16 14:59 •
647次
阅读
使用Python实现五个自动化场景
相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大....
牵手一起梦 发表于 03-16 14:59 •
647次
阅读
使用Python实现五个自动化场景
相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大....
![的头像]() Linux爱好者 发表于 03-16 11:13 •
153次
阅读
使用AioHttp异步抓取火星图片
让我们从一个简单的应用程序开始,只是为了启动和运行aiohttp。首先,创建一个新的virtuale....
Linux爱好者 发表于 03-16 11:13 •
153次
阅读
使用AioHttp异步抓取火星图片
让我们从一个简单的应用程序开始,只是为了启动和运行aiohttp。首先,创建一个新的virtuale....
![的头像]() 马哥Linux运维 发表于 03-16 09:58 •
152次
阅读
如何用python爬取抖音app数据
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例。
马哥Linux运维 发表于 03-16 09:58 •
152次
阅读
如何用python爬取抖音app数据
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例。
![的头像]() 马哥Linux运维 发表于 03-16 09:07 •
190次
阅读
python创建多线程的两种方法
1. 用函数创建多线程在Python3中,Python提供了一个内置模块 threading.Thread,可以很方便地让我们创建多线程。
threading....
发表于 03-15 16:47 •
989次
阅读
python创建多线程的两种方法
1. 用函数创建多线程 在Python3中,Python提供了一个内置模块 threading.Th....
马哥Linux运维 发表于 03-16 09:07 •
190次
阅读
python创建多线程的两种方法
1. 用函数创建多线程在Python3中,Python提供了一个内置模块 threading.Thread,可以很方便地让我们创建多线程。
threading....
发表于 03-15 16:47 •
989次
阅读
python创建多线程的两种方法
1. 用函数创建多线程 在Python3中,Python提供了一个内置模块 threading.Th....
![的头像]() python爬虫知识分享 发表于 03-15 16:47 •
331次
阅读
python多线程和多进程对比
1. 基本概念在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白,更通俗易懂。
串行:一个...
发表于 03-15 16:42 •
462次
阅读
python多线程和多进程的对比
1. 基本概念 在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白....
python爬虫知识分享 发表于 03-15 16:47 •
331次
阅读
python多线程和多进程对比
1. 基本概念在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白,更通俗易懂。
串行:一个...
发表于 03-15 16:42 •
462次
阅读
python多线程和多进程的对比
1. 基本概念 在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白....
![的头像]() python爬虫知识分享 发表于 03-15 16:42 •
322次
阅读
python爬虫知识分享 发表于 03-15 16:42 •
322次
阅读
 基于Python语言的RFM模型讲解
上面步骤可以知道,我们需要有RFM三个维度,根据我们在业务分析方法课程中学到的,业务分析模型离不开指....
基于Python语言的RFM模型讲解
上面步骤可以知道,我们需要有RFM三个维度,根据我们在业务分析方法课程中学到的,业务分析模型离不开指....
![的头像]() 数据分析与开发 发表于 03-15 15:38 •
185次
阅读
一文理解python模块的缓存
在一个模块内部重复引用另一个相同模块,实际并不会导入两次,原因是在使用关键字 import 导入模块....
数据分析与开发 发表于 03-15 15:38 •
185次
阅读
一文理解python模块的缓存
在一个模块内部重复引用另一个相同模块,实际并不会导入两次,原因是在使用关键字 import 导入模块....
![的头像]() python爬虫知识分享 发表于 03-14 16:42 •
194次
阅读
关于python包导入的三个冷门知识点
使用 from module import * 默认情况下会导入 module 里的所有变量,若你只....
python爬虫知识分享 发表于 03-14 16:42 •
194次
阅读
关于python包导入的三个冷门知识点
使用 from module import * 默认情况下会导入 module 里的所有变量,若你只....
![的头像]() python爬虫知识分享 发表于 03-14 16:33 •
226次
阅读
图数据平台Neo4j线上直播将于3月23日举行
随着大数据、高性能计算、虚拟仿真、大数据计算的快速发展,网络和IT基础架构的规模和复杂性管理数据库比....
发表于 03-11 16:08 •
14次
阅读
一文了解pip的超全使用指南
由于默认情况下,wheel 包的平台是运行 pip download 命令 的平台,所以可能出现平台....
python爬虫知识分享 发表于 03-14 16:33 •
226次
阅读
图数据平台Neo4j线上直播将于3月23日举行
随着大数据、高性能计算、虚拟仿真、大数据计算的快速发展,网络和IT基础架构的规模和复杂性管理数据库比....
发表于 03-11 16:08 •
14次
阅读
一文了解pip的超全使用指南
由于默认情况下,wheel 包的平台是运行 pip download 命令 的平台,所以可能出现平台....
![的头像]() python爬虫知识分享 发表于 03-11 16:03 •
266次
阅读
详解python常规包与命名空间包
python常规包与命名空间包 1. 常规包 在 Python 3.3 之前或者说 Python 2....
python爬虫知识分享 发表于 03-11 16:03 •
266次
阅读
详解python常规包与命名空间包
python常规包与命名空间包 1. 常规包 在 Python 3.3 之前或者说 Python 2....
![的头像]() python爬虫知识分享 发表于 03-11 15:46 •
268次
阅读
Smartbi推出一站式高校大数据解决方案
在本文中,Smartbi基于多年来在高校大数据建设的经验,提出了“1个中心+N个应用”的一站式解决方....
发表于 03-11 15:02 •
16次
阅读
python花式导包的八种方法
python花式导包的八种方法 1. 直接 import 人尽皆知的方法,直接导入即可 import....
python爬虫知识分享 发表于 03-11 15:46 •
268次
阅读
Smartbi推出一站式高校大数据解决方案
在本文中,Smartbi基于多年来在高校大数据建设的经验,提出了“1个中心+N个应用”的一站式解决方....
发表于 03-11 15:02 •
16次
阅读
python花式导包的八种方法
python花式导包的八种方法 1. 直接 import 人尽皆知的方法,直接导入即可 import....
![的头像]() python爬虫知识分享 发表于 03-10 16:48 •
233次
阅读
python安装第三方包的八种方法
python安装第三方包的八种方法 1. 使用 easy_install easy_install ....
python爬虫知识分享 发表于 03-10 16:48 •
233次
阅读
python安装第三方包的八种方法
python安装第三方包的八种方法 1. 使用 easy_install easy_install ....
![的头像]() python爬虫知识分享 发表于 03-10 16:27 •
238次
阅读
易华录获“非接触式面部表情分析系统”一等奖
在江苏省公安厅主办的“2021年度省厅科技强警奖”评选中,经过层层筛选、现场评审、网上公示等环节,易....
python爬虫知识分享 发表于 03-10 16:27 •
238次
阅读
易华录获“非接触式面部表情分析系统”一等奖
在江苏省公安厅主办的“2021年度省厅科技强警奖”评选中,经过层层筛选、现场评审、网上公示等环节,易....
![的头像]() 易华录 发表于 03-10 16:07 •
393次
阅读
易华录推食品安全智慧监管解决方案
为督促落实食品安全党政同责和“四个最严”,鼓励地方政府发挥首创精神,国务院食品安全委员会办公室于20....
易华录 发表于 03-10 16:07 •
393次
阅读
易华录推食品安全智慧监管解决方案
为督促落实食品安全党政同责和“四个最严”,鼓励地方政府发挥首创精神,国务院食品安全委员会办公室于20....
![的头像]() 易华录 发表于 03-10 16:01 •
721次
阅读
紫光国微加入中国开放指令生态 星环科技签署战略合作协议
近日,紫光国微凭借在智慧芯片领域积累的深厚实力,正式成为中国开放指令生态(RISC-V)联盟会员单位....
发表于 03-10 15:52 •
515次
阅读
希捷科技孙丹连续三年入选福布斯“中国杰出商界女性100”榜单
近日,福布斯中国公布了2022中国杰出商界女性排行榜。希捷科技全球高级副总裁暨中国区总裁孙丹女士连续....
易华录 发表于 03-10 16:01 •
721次
阅读
紫光国微加入中国开放指令生态 星环科技签署战略合作协议
近日,紫光国微凭借在智慧芯片领域积累的深厚实力,正式成为中国开放指令生态(RISC-V)联盟会员单位....
发表于 03-10 15:52 •
515次
阅读
希捷科技孙丹连续三年入选福布斯“中国杰出商界女性100”榜单
近日,福布斯中国公布了2022中国杰出商界女性排行榜。希捷科技全球高级副总裁暨中国区总裁孙丹女士连续....
![的头像]() 人间烟火123 发表于 03-10 13:54 •
229次
阅读
2022浪潮信息生态伙伴大会即将举行
2022浪潮信息生态伙伴大会(IPF22)将于3月17-18日在线上举行。本届大会以“智算创见 数实....
人间烟火123 发表于 03-10 13:54 •
229次
阅读
2022浪潮信息生态伙伴大会即将举行
2022浪潮信息生态伙伴大会(IPF22)将于3月17-18日在线上举行。本届大会以“智算创见 数实....
![的头像]() 浪潮存储 发表于 03-09 18:06 •
3577次
阅读
基于深度学习技术的电表大数据检测系统
基于深度学习技术的电表大数据检测系统 来源:《 人工智能与机器人研究》 ,作者方向 摘要: 随....
发表于 03-09 16:49 •
20次
阅读
python包、模块和库是什么
1. 模块 以 .py 为后缀的文件,我们称之为 模块,英文名 Module。 模块让你能够有逻辑地....
浪潮存储 发表于 03-09 18:06 •
3577次
阅读
基于深度学习技术的电表大数据检测系统
基于深度学习技术的电表大数据检测系统 来源:《 人工智能与机器人研究》 ,作者方向 摘要: 随....
发表于 03-09 16:49 •
20次
阅读
python包、模块和库是什么
1. 模块 以 .py 为后缀的文件,我们称之为 模块,英文名 Module。 模块让你能够有逻辑地....
![的头像]() python爬虫知识分享 发表于 03-09 16:47 •
248次
阅读
python类的多态和类的property属性
python类的多态 多态,是指在同一类型下的不同形态。 比如下面这段代码 class People....
python爬虫知识分享 发表于 03-09 16:47 •
248次
阅读
python类的多态和类的property属性
python类的多态 多态,是指在同一类型下的不同形态。 比如下面这段代码 class People....
![的头像]() python爬虫知识分享 发表于 03-09 16:37 •
226次
阅读
对比学习的关键技术和基本应用分析
对比学习的主要思想是相似的样本的表示相近,而不相似的远离。对比学习可以应用于监督和无监督的场景下,并....
python爬虫知识分享 发表于 03-09 16:37 •
226次
阅读
对比学习的关键技术和基本应用分析
对比学习的主要思想是相似的样本的表示相近,而不相似的远离。对比学习可以应用于监督和无监督的场景下,并....
![的头像]() 深度学习自然语言处理 发表于 03-09 16:28 •
272次
阅读
用Python学习科学编程
用Python学习科学编程,Python经典教材。
发表于 03-09 15:00 •
42次
阅读
中华环保联合会标准编写工作会在大华股份召开
3月4日,中华环保联合会标准编写工作会在大华隆重召开,来自全国各地生态环保领域的领导、专家学者及企业....
深度学习自然语言处理 发表于 03-09 16:28 •
272次
阅读
用Python学习科学编程
用Python学习科学编程,Python经典教材。
发表于 03-09 15:00 •
42次
阅读
中华环保联合会标准编写工作会在大华股份召开
3月4日,中华环保联合会标准编写工作会在大华隆重召开,来自全国各地生态环保领域的领导、专家学者及企业....
![的头像]() 大华股份 发表于 03-09 14:30 •
641次
阅读
深度学习在轨迹数据挖掘中的应用研究综述
深度学习在轨迹数据挖掘中的应用研究综述 来源:《 计算机科学与应用》 ,作者 李旭娟 等 摘要: ....
发表于 03-08 17:24 •
48次
阅读
大华股份 发表于 03-09 14:30 •
641次
阅读
深度学习在轨迹数据挖掘中的应用研究综述
深度学习在轨迹数据挖掘中的应用研究综述 来源:《 计算机科学与应用》 ,作者 李旭娟 等 摘要: ....
发表于 03-08 17:24 •
48次
阅读
 python类的继承详解
python类的继承 类的继承,跟人类繁衍的关系相似。 被继承的类称为基类(也叫做父类),继承而得的....
python类的继承详解
python类的继承 类的继承,跟人类繁衍的关系相似。 被继承的类称为基类(也叫做父类),继承而得的....
![的头像]() python爬虫知识分享 发表于 03-08 16:40 •
396次
阅读
python私有变量和私有方法
python私有变量和私有方法 1. 下划线妙用 在 Python 中,下划线可是非常推荐使用的符号....
python爬虫知识分享 发表于 03-08 16:40 •
396次
阅读
python私有变量和私有方法
python私有变量和私有方法 1. 下划线妙用 在 Python 中,下划线可是非常推荐使用的符号....
![的头像]() python爬虫知识分享 发表于 03-08 16:30 •
460次
阅读
商业智能BI在银行业的应用
商业智能BI是信息化发展的必然产物。在信息化过程中,企业将根据需要建立各种业务体系,提高日常运行效率....
发表于 03-08 11:43 •
21次
阅读
python静态方法与类方法
python静态方法与类方法 1. 写法上的差异 类的方法可以分为: 静态方法:有 staticme....
python爬虫知识分享 发表于 03-08 16:30 •
460次
阅读
商业智能BI在银行业的应用
商业智能BI是信息化发展的必然产物。在信息化过程中,企业将根据需要建立各种业务体系,提高日常运行效率....
发表于 03-08 11:43 •
21次
阅读
python静态方法与类方法
python静态方法与类方法 1. 写法上的差异 类的方法可以分为: 静态方法:有 staticme....
![的头像]() python爬虫知识分享 发表于 03-07 16:56 •
451次
阅读
python类的理解与使用
python类的理解与使用 1. 通俗理解类 类(英文名 class),是具有相同特性(属性)和行为....
python爬虫知识分享 发表于 03-07 16:56 •
451次
阅读
python类的理解与使用
python类的理解与使用 1. 通俗理解类 类(英文名 class),是具有相同特性(属性)和行为....
![的头像]() python爬虫知识分享 发表于 03-07 16:51 •
427次
阅读
卷积神经网络结构优化综述
卷积神经网络结构优化综述 来源:《自动化学报》 ,作者林景栋等 摘 要 近年来,卷积神经网络(C....
发表于 03-07 16:42 •
26次
阅读
云豹智能与燧原科技达成战略合作 瓦克成为汽车制造业一级供应商
近日,金山云公司核心PaaS产品再获行业权威机构的认可,此次入选的DragonBase分布式数据库,....
发表于 03-07 13:55 •
770次
阅读
一种改进的高光谱图像CEM目标检测算法
一种改进的高光谱图像CEM目标检测算法 来源:《 应用物理》 ,作者付铜铜等 摘要: 约束能量....
发表于 03-05 15:47 •
26次
阅读
python如何捕获异常和主动抛出异常
python如何主动抛出异常和捕获异常 1. 如何抛出异常? 异常的产生有两种来源: 一种是程序自动....
python爬虫知识分享 发表于 03-07 16:51 •
427次
阅读
卷积神经网络结构优化综述
卷积神经网络结构优化综述 来源:《自动化学报》 ,作者林景栋等 摘 要 近年来,卷积神经网络(C....
发表于 03-07 16:42 •
26次
阅读
云豹智能与燧原科技达成战略合作 瓦克成为汽车制造业一级供应商
近日,金山云公司核心PaaS产品再获行业权威机构的认可,此次入选的DragonBase分布式数据库,....
发表于 03-07 13:55 •
770次
阅读
一种改进的高光谱图像CEM目标检测算法
一种改进的高光谱图像CEM目标检测算法 来源:《 应用物理》 ,作者付铜铜等 摘要: 约束能量....
发表于 03-05 15:47 •
26次
阅读
python如何捕获异常和主动抛出异常
python如何主动抛出异常和捕获异常 1. 如何抛出异常? 异常的产生有两种来源: 一种是程序自动....
![的头像]() python爬虫知识分享 发表于 03-04 17:09 •
692次
阅读
Python中有哪些常见的错误和异常
python常见异常类型 在程序运行过程中,总会遇到各种各样的问题和错误。 有些错误是我们编写代码时....
python爬虫知识分享 发表于 03-04 17:09 •
692次
阅读
Python中有哪些常见的错误和异常
python常见异常类型 在程序运行过程中,总会遇到各种各样的问题和错误。 有些错误是我们编写代码时....
![的头像]() python爬虫知识分享 发表于 03-04 16:58 •
712次
阅读
python爬虫知识分享 发表于 03-04 16:58 •
712次
阅读
|